When building applications in a microservice architecture, managing state becomes a distributed systems problem. Instead of being able to manage state as transactions inside the boundaries of a single monolithic application, a microservice must be able to manage consistency using transactions that are distributed across a network of many different applications and databases.
In this article we will explore the problems of data consistency and high availability in microservices. We will start by taking a look at some of the important concepts and themes behind handling data consistency in distributed systems.
Throughout this article we will use a reference application of an online store that is built with microservices using Spring Boot and Spring Cloud. We’ll then look at how to use reactive streams with Project Reactor to implement event sourcing in a microservice architecture. Finally, we’ll use Docker and Maven to build, run, and orchestrate the multi-container reference application.
Eventual Consistency
When building microservices, we are forced to start reasoning about state in an architecture where data is eventually consistent. This is because each microservice exclusively exposes resources from a database that it owns. Further, each of these databases would be configured for high availability, with different consistency guarantees for each type of database.
Eventual consistency is a model that is used to describe some operations on data in a distributed system—where state is replicated and stored across multiple nodes of a network. Typically, eventual consistency is talked about when running a database in high availability mode, where replicas are maintained by coordinating writes between multiple nodes of a database cluster. The challenge of the database cluster is that writes must be coordinated to all replicas in the exact order that they were received. When this happens, each replica is considered to be eventually consistent—that the state of all replicas are guaranteed to converge towards a consistent state at some point in the future.
When first building microservices, eventual consistency is a frequent point of contention between developers, DBAs, and architects. The head scratching starts to occur more frequently when the architecture design discussions begin to turn to the topic of data and handling state in a distributed system. The head scratching usually boils down to one question.
How can we guarantee high availability while also guaranteeing data consistency?
To answer this question we need to understand how to best handle transactions in a distributed system. It just so happens that most distributed databases have this problem nailed down with a healthy helping of science.
Transaction Logs
Mostly all databases today support some form of high availability clustering. Most database products will provide a list of easy to understand guarantees about a system’s consistency model. A first step to achieving safety guarantees for stronger consistency models is to maintain an ordered log of database transactions. This approach is pretty simple in theory. A transaction log is an ordered record of all updates that were transacted by the database. When transactions are replayed in the exact order they were recorded, an exact replica of a database can be generated.

The diagram above represents three databases in a cluster that are replicating data using a shared transaction log. The zipper labeled Primary is the authority in this case and has the most current view of the database. The difference between the zippers represent the consistency of each replica, and as the transactions are replayed, each replica converges to a consistent state with the Primary. The basic idea here is that with eventual consistency, all zippers will eventually be zipped all the way up.
The transaction logs that databases use actually have deep roots in history that pre-dates computing. The fundamental approach for managing an ordered log of transactions was first used by Venetian merchants as far back as the 15th century. The method that these Venetian merchants started using was called the double-entry bookkeeping system—which is a system of bookkeeping that requires two side-by-side entries for each transaction. For each of these transactions, both a credit and a debit are specified from an origin account to a destination account. To calculate the balance of an account, any merchant could simply replicate the current state of all accounts by replaying the events recorded in the ledger. This same fundamental practice of bookkeeping is still used today, and to some extent its a basic concept for transaction management in modern database systems.
For databases that claim to have eventual consistency, it’s guaranteed that each node in the database cluster will converge towards a globally consistent state by simply replaying the transaction log that resulted from a merge of write transactions across replicas. This claim, however, is only a guarantee of a database’s liveness properties, ignoring any guarantees about its safety properties. The difference between safety and liveness here is that with eventual consistency we can only be guaranteed that all updates will be observed eventually, with no guarantee about correctness.
Most content available today that attempts to educate us on the benefits of microservices will contain a very sparse explanation behind the saying that "microservices use eventual consistency"—sometimes referencing CAP theorem to bolster any sense of existing confusion. This tends to be a shallow explanation that leads to more questions than answers. A more appropriate explanation of eventual consistency in microservices would be the following statement.
Microservice architectures provide no guarantees about the correctness of your data.
The only consistency guarantee you’ll get with microservices is that all microservices will eventually agree on something—correct or not.
Cutting through the vast hype that exists on the road to building microservices is not only important, it is an assured eventuality that all developers must face. This is because when it comes to building software, a distributed system is a distributed system. A collection of communicating microservices are no exception. The good news is, there are tried and true patterns for how to successfully build and maintain complex distributed systems, and that’s the main theme of the rest of this article.
Event Sourcing
Event sourcing is a method of data persistence that borrows similar ideas behind a database’s transaction log. For event sourcing, the unit of a transaction becomes much more granular, using a sequence of ordered events to represent the state of a domain object stored in a database. Once an event has been added to to the event log, it cannot be removed or re-ordered. Events are considered to be immutable and the sequence of events that are stored are append-only.
There are multiple benefits for handling state in a microservice architecture using event sourcing.
-
Aggregates can be used to generate the consistent state of any object
-
It provides an audit trail that can be replayed to generate the state of an object from any point in time
-
It provides the many inputs necessary for analyzing data using event stream processing
-
It enables the use of compensating transactions to rollback events leading to an inconsistent application state
-
It also avoids complex synchronization between microservices, paving the way for asynchronous non-blocking operations between microservices
In this article we’re going to look at a JVM-based implementation of event sourcing that uses Spring Cloud and Spring Boot. As with most of the articles you’ll find on this blog, we’re going to take a tour of a realistic sample application that you can run and deploy. This time I’ve put together an example of an end-to-end cloud native application using microservices. I’ve even included an AngularJS frontend, thanks to some very clever ground work by Dr. Dave Syer on the Spring Engineering team. (Thanks Dr. Syer!)
Reference Application
As I mentioned earlier, this reference application was designed as a cloud native application. Cloud native applications and architectures are designed and built using a set of standard methodologies that maximize the utility of a cloud platform. Cloud native applications use something called twelve-factor application methodology. The twelve-factor methodology is a set of practices and useful guidelines that were compiled by the engineers behind Heroku, which have become a standard reference for creating applications suitable to be deployed to a cloud platform.
Cloud native application architectures will typically embrace scale-out infrastructure principles, such as horizontal scaling of applications and databases. Applications also focus on building in resiliency and auto-healing to prevent downtime. Through the use of a platform, availability can be automatically adjusted as necessary using a set of policies. Also, load balancing for services are shifted to the client-side, and handled between applications, preventing the need to configure load balancers for new application instances.
Online Store Web
I’ve taken big leaps from the other microservice reference applications you’ll find here on this blog. This application was created to demonstrate a fully formed microservice architecture that implements the core functionality of an online store.
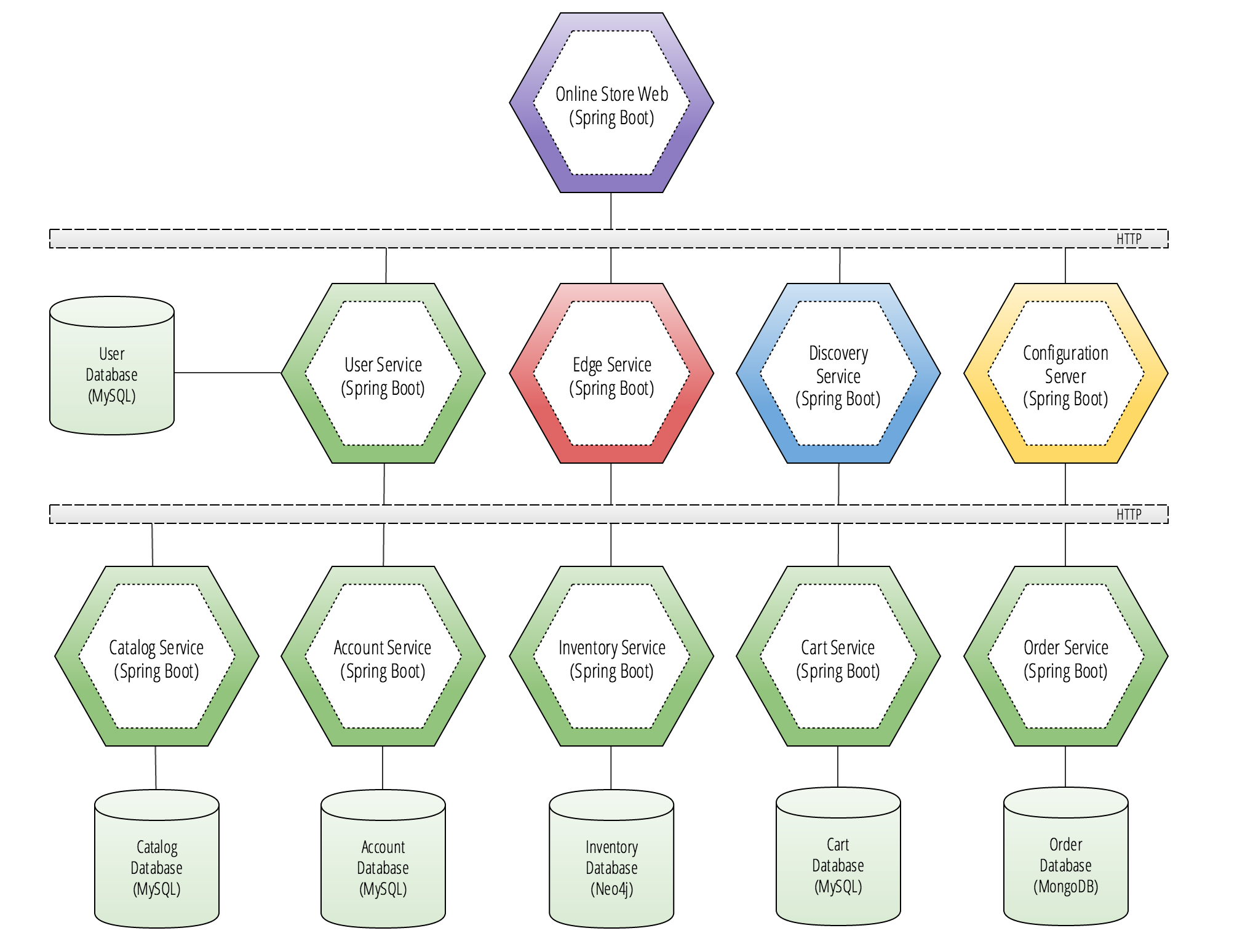
Users of this online store application will be interacting with a front-end website that is hosted on Online Store Web, which is a Spring Boot application, and is the service colored purple in the diagram above. This application houses the static content of an AngularJS site.
The main challenge with writing a front-end application on a back-end of microservices, when using a client-side JavaScript framework like AngularJS, is how to safely expose REST APIs on the same host that houses the static JS content. We need to solve this challenge in order to prevent security vulnerabilities that could result from making our back-end REST APIs publicly accessible from multiple domains. If we were to host these microservices on separate domains, we would be required to enable Cross-origin resource sharing (CORS), which would make our application’s backend vulnerable to various forms of attack.
In order to solve the problem of CORS, we have a suite of excellent tools at our disposal, all of which are a part of the Spring Cloud project ecosystem.
Spring Cloud Backing Services
Looking back at the reference architecture’s diagram, we see that Online Store Web has direct HTTP connections to 4 other applications in the middle layer. These services are:

Each of these Spring Boot applications are considered to be backing services to the Online Store Web application. The Backing service is a term that was popularized in the twelve-factor methodology. The premise is that there are third-party service dependencies that should be treated as attached resources to your cloud native applications. The key trait of backing services are that they are provided as bindings to an application in its deployment environment by a cloud platform.
The 4 backing services in the diagram will be bound to the Online Store Web when it is run in the deployment’s target environment. A cloud platform, such as the popular open source PaaS Cloud Foundry, will provide the application with secure credentials and URIs as externalized configuration properties that take the form of injected environment variables.
The reason these backing services differ from the bottom layer in the diagram is that each of the backing services must be located using a statically defined route that can be injected as an environment variable to the Online Store Web application’s container. Backing services always have this defining trait. This approach is considered a standard practice for providing a production application with secure credentials to connect to a database or service. The rule here is: if it cannot be discovered using a discovery service and has a statically defined route that one of your application deployments will depend on, then it’s considered to be a backing service for that environment.
Going back to the diagram, the services in the bottom layer do not need to have any statically defined route to be located. As long as the four backing services are locatable with an address, the bottom layer services can all be discovered through the backing services using the Discovery Service and the Edge Service.
User Service
The User Service is the authentication gateway that protects back-end resources in the application’s microservice architecture. There are two methods in which resources are exposed to a front-end application: protected and unprotected. A protected resource is one that requires user-level authentication. An unprotected resource is usually a read-only set of resources that can be viewed by users who are not authenticated, such as a product catalog.

The User Service also houses a Spring Cloud OAuth2 authorization server as well as a resource server. It is this service that all other applications in the target environment will be able to use to retrieve and validate token information. The token information that is validated will automatically be provided in the headers of requests to protected resources and used to authenticate a user’s session.
If the user does not provide authentication details in the header of a request to protected resources, they will be redirected to the User Service login page where they will be able to sign in securely and authorize a grant to obtain an access token.
Edge Service
The Edge Service is a Spring Cloud application that is responsible for securely exposing HTTP routes from backend microservices. The Edge Service is a very important component in a Spring Cloud microservices architecture, as it provides frontend applications a way to expose every API from the backend services as a single unified REST API.

To take advantage of the Edge Service, a Spring Boot application would simply attach it as a backing service in the target environment. In doing this, the Edge Service will provide secure authenticated access to all REST APIs that are exposed by the backend services. To be able to do this, the Edge Service matches a request route’s URL fragment from a front-end application to a back-end microservice through a reverse proxy to retrieve the remote REST API response.
The end result is that the Edge Service provides a seamless REST API that will become embedded in any Spring Boot application that attaches it as a backing service using Spring Cloud Netflix’s Zuul starter project.
Discovery Service
The Discovery Service is a Spring Cloud application that is responsible for maintaining a registry of service information in a target environment. Each service application will subscribe to a Discovery Service application in the target environment at start-up. The subscribing application will then provide its local networking information, which includes its network address. By doing this, all other applications in the environment will be able to locate other subscribers by downloading a service registry and caching it locally. The local service registry will be used on an as-needed basis to retrieve the network address of other services that an application depends on in the target environment.

Configuration Server
The Configuration Server is a Spring Cloud application that centralizes external configurations using various methodologies of building twelve-factor applications. The twelve-factor app stores configurations in the environment and not in the project’s source code. This service will allow other applications to retrieve their tailored configurations for the target environment.
Backend Microservices
While the backing services in the middle layer are still considered to be microservices, they solve a set of concerns that are purely operational and security-related. The business logic of this application sits almost entirely in our bottom layer. These applications are designed around business capabilities of the fictitious online store, which I’ve gone ahead and branded as Cloud Native Outfitters–a hypothetical Silicon Valley startup that sells 4 really clever t-shirts and hoodies.
As a part of the business capabilities of the online store, we have the following 5 microservices that will serve as our backend REST API. The main consumer of these APIs is the Online Store Web, as well as other planned customer facing applications that may never see the light of day in the case that Cloud Native Outfitters is unable to secure a seed round of investment from one of the top-tier venture capital firms on Sand Hill Road.
Each of these microservices will be exposed as a seamless REST API via the Edge Service application in the middle layer. The Edge Service uses Spring Cloud Netflix’s Zuul proxy to map request routes from the Online Store Web application to the appropriate backend microservice’s REST API.
These applications can be found at:

A description of the role of each of these microservices is explained in the GitHub repository for this sample project. I’ll be regularly contributing to the applications in this project’s repository for future articles that will focus on more of the patterns and best practices of microservice architectures.
The next part of this article is going to focus on the original topic of event sourcing in microservices using Spring Boot, Spring Cloud, and Project Reactor.
Project Reactor
Project Reactor is an open source library for building JVM applications based on the Reactive Streams Specification and is a member of the Spring ecosystem of maintained open source libraries. The purpose of Reactor is to provide developers that are building JVM-based applications with a Reactive library that is dedicated to building non-blocking applications—and as a result help us tackle the problem of unnecessary latency.
It is very common for applications interfacing with microservices to call multiple other microservices during the same execution context. As we talked about earlier, one of the key traits of a microservice architecture is eventual consistency. While eventual consistency does not provide any guarantees about the safety of our data, it does provide us with the option to use asynchronous non-blocking operations when communicating with other microservices in the same execution context. This is where the Reactor libraries become very useful.
There are some rare situations, if any, where the state of a domain object must be shared across microservices. When using Event Sourcing in microservices we will only store a log of strictly ordered events. By taking this approach there should be very limited situations where there is a requirement to store the state of a domain object in a database. Instead, we are resolved to only store a stream of ordered events representing the aggregate state of an object. By doing this, it means we will have eliminated a majority of scenarios where we need to synchronize state with other microservices using RESTful APIs that use HTTP. These types of blocking operations are at the root of a variety of latency issues when communicating between microservices.
Event Sourcing with Reactor Core
One of the microservices in the online store is the Shopping Cart Service. Authenticated users browse the product catalog from the user interface of the Online Store Web application. The users are able to add and remove product line items from their shopping cart as well as clear their cart or checkout.

A user’s shopping cart paints a simple picture of how event sourcing works. The Shopping Cart Service is the owner of a MySQL database that has a table called cart_event. This table contains an ordered log of events that a user has generated in the response to an action, with the purpose of managing the items in their shopping cart.
// These will be the events that are stored in the event log for a cart
public enum CartEventType {
ADD_ITEM,
REMOVE_ITEM,
CLEAR_CART,
CHECKOUT
}Let’s consider that the CartEventType is an enum that has a list of 4 different event types. Each of these event types represent an action performed by a user on their shopping cart. With event sourcing, these cart events can each impact the outcome of the final state of a user’s shopping cart. When a user adds or removes an item to their cart, the action produces an event that increments or decrements the aggregate quantity of a line item. When these events are replayed in the same order as they were received, a list of product line items are created, each with a corresponding quantity value.
The following table is an export of an event log that represents a user’s actions on their shopping cart.
| id | created_at | last_modified | cart_event_type | product_id | quantity | user_id |
|---|---|---|---|---|---|---|
| 1 | 1460990971645 | 1460990971645 | 0 | SKU-12464 | 2 | 0 |
| 2 | 1460992816398 | 1460992816398 | 1 | SKU-12464 | 1 | 0 |
| 3 | 1460992826474 | 1460992826474 | 0 | SKU-12464 | 2 | 0 |
| 4 | 1460992832872 | 1460992832872 | 0 | SKU-12464 | 2 | 0 |
| 5 | 1460992836027 | 1460992836027 | 1 | SKU-12464 | 5 | 0 |
We see from this table that each row has a unique timestamp to ensure strict ordering. We also see an integer representing the 4 CartEventType enum types. There is also some meta-data that is stored in this table. The columns product_id and quantity are both used to generate the aggregate shopping cart and product line items.

The result of this is shown in the above screenshot. Here we see a user’s shopping cart that was generated as an aggregate object.
Choosing an Event Store
There are many options available when choosing an appropriate storage option for event sourcing. Mostly all databases today that provide streaming query capabilities will work. There are however some popular open source projects that stand out for this use case. One example of a project that is increasingly becoming the standard for event sourcing architectures is Apache Kafka, which is a subject of a future blog post. For this example we’re going to use MySQL, which is a fine choice for implementing event sourcing for an online shopping cart.
| The choice of technology for your event store will always depend on the volume of writes and the throughput of your database. A project like Apache Kafka was designed for this exact use case but it requires us to take on some additional operational responsibility to scale it in production, including running an Apache ZooKeeper cluster. |
Generating Aggregates
In the Shopping Cart Service we will provide a versioned REST API that implements a method for accepting new events from the Online Store Web application.
@RequestMapping(path = "/events", method = RequestMethod.POST)
public ResponseEntity addCartEvent(@RequestBody CartEvent cartEvent) throws Exception {
return Optional.ofNullable(shoppingCartService.addCartEvent(cartEvent))
.map(event -> new ResponseEntity(HttpStatus.NO_CONTENT))
.orElseThrow(() -> new Exception("Could not find shopping cart"));
}In the code example above we define a controller method for collecting new CartEvent objects from clients. The purpose of this method will be to append additional cart events to the event log in our cart_event table. The result is that when clients then call the REST API method for retrieving a user’s shopping cart, it will be generated as an aggregate that incorporates all cart events using reactive streaming.
The next step is generating the aggregate of cart events using Reactor.
public ShoppingCart aggregateCartEvents(User user, Catalog catalog) throws Exception {
// Create a reactive streams publisher by streaming ordered events from the database
Flux<CartEvent> cartEvents =
Flux.fromStream(cartEventRepository.getCartEventStreamByUser(user.getId()));
// Aggregate the current state of the shopping cart until arriving at a terminal state in the stream
ShoppingCart shoppingCart = cartEvents
.takeWhile(cartEvent -> !ShoppingCart.isTerminal(cartEvent.getCartEventType()))
.reduceWith(() -> new ShoppingCart(catalog), ShoppingCart::incorporate)
.get();
// Generate the list of line items in the cart from the aggregate
shoppingCart.getLineItems();
return shoppingCart;
}In the code example above we see three steps to generate the shopping cart object and return it back to a client. The first step is to create a reactive stream from the data source of the event store for cart events. Once the stream has been established, we can begin to incorporate each event in the stream to generate our aggregate. The reactive stream that is created will take each event from the data store and mutate the state of the ShoppingCart until it eventually arrives at the terminating state, which gives us our final aggregate view of the user’s shopping cart.
In the reduce phase of the reactive stream’s aggregation we use a method called incorporate that belongs to the ShoppingCart class. This method accepts a CartEvent object which is used to mutate the state of the ShoppingCart.
public ShoppingCart incorporate(CartEvent cartEvent) {
// Remember that thing about safety properties in microservices?
Flux<CartEventType> validCartEventTypes =
Flux.fromStream(Stream.of(CartEventType.ADD_ITEM,
CartEventType.REMOVE_ITEM));
// The CartEvent's type must be either ADD_ITEM or REMOVE_ITEM
if (validCartEventTypes.exists(cartEventType ->
cartEvent.getCartEventType().equals(cartEventType)).get()) {
// Update the aggregate view of each line item's quantity from the event type
productMap.put(cartEvent.getProductId(),
productMap.getOrDefault(cartEvent.getProductId(), 0) +
(cartEvent.getQuantity() * (cartEvent.getCartEventType()
.equals(CartEventType.ADD_ITEM) ? 1 : -1)));
}
// Return the updated state of the aggregate to the reactive stream's reduce method
return this;
}In the code example above we see the implementation of the incorporate method for a ShoppingCart. Here we accept a CartEvent object and then take a very important step to ensure data safety by validating that the event’s type. This is where microservices need to be liberal with their unit testing to ensure that state mutation will ensure data correctness in an eventually consistent architecture. In this case, we ensure that the event types are either ADD_ITEM or REMOVE_ITEM.
The next step is to update the aggregate view of each line item in the shopping cart by mapping the corresponding event types to an increment or decrement value that can be applied to the line item’s quantity. Finally, we return the current view back to the client with the mutated state that resulted in incorporating the new event.
Docker Compose Demo
The example project uses Docker Compose to build and run a container image of each of our microservices as a part of the Maven build process.
Getting Started
To get started, visit the GitHub repository for this example project.
Clone or fork the project and download the repository to your machine. After downloading, you will need to use both Maven and Docker to compile and build the images locally.
Download Docker
First, download Docker if you haven’t already. Follow the instructions found here, to get Docker toolbox up and running on your development machine.
After you’ve installed Docker toolbox, run the following command to initialize a new virtualbox VM for this sample application.
$ docker-machine create event-source-demo --driver virtualbox --virtualbox-memory "11000" --virtualbox-disk-size "100000"
$ eval "$(docker-machine env event-source-demo)"Requirements
The requirements for running this demo on your machine are found below.
-
Maven 3
-
Java 8
-
Docker
-
Docker Compose
Building the project
To build the project, from the terminal, run the following command at the root of the project.
$ sh run.shThe project will then download all of the needed dependencies and compile each of the project artifacts. Each service will be built, and then a Maven Docker plugin will automatically build each of the images into your local Docker registry. Docker must be running and available from the command line where you run the sh run.sh command for the build to succeed.
Start the Cluster with Docker Compose
Now that each of the images has been built successfully, we can using Docker Compose to spin up our cluster. The run.sh script will build each of the projects and Docker containers which will be used by Docker Compose to start each of the services. The services that need to be started first are the Configuration Service and the Discovery Service. The rest of the services will then begin to start up and eventually begin to communicate with each other.
| I highly recommend that you run this sample on a machine with at least 16GB of system memory. |
Once the startup sequence is completed, you can navigate to the Eureka host and see which services have registered with the discovery service.
Copy and paste the following command into the terminal where Docker can be accessed using the $DOCKER_HOST environment variable.
$ open $(echo \"$(echo $DOCKER_HOST)\"|
\sed 's/tcp:\/\//http:\/\//g'|
\sed 's/[0-9]\{4,\}/8761/g'|
\sed 's/\"//g')When the user interface successfully loads for Eureka, you’ll see the list of services that have registered as a Eureka discovery client.

When all applications have finished starting and are registered with Eureka, you can access the Online Store Web application using the following command.
$ open $(echo \"$(echo $DOCKER_HOST)\"|
\sed 's/tcp:\/\//http:\/\//g'|
\sed 's/[0-9]\{4,\}/8787/g'|
\sed 's/\"//g')| It may take some time for the application to start up, so make sure you refresh the UI every few minutes until the product catalog becomes visible. |

To start adding products to the shopping cart, you’ll need to login with the default user. Click Login and you’ll be redirected to the authentication gateway. Use the default credentials of user and password to login.

You’ll be redirected to the home page where you will now be authenticated and can begin to manage items in your shopping cart.

Conclusion
In this article we took a hard look at the challenges of high availability and data consistency in microservice architectures. We looked at a full cloud native application of an online store as a collection of microservices that use event sourcing to maintain a consistent view of the world while still guaranteeing high availability.
In upcoming blog posts I will be exploring how to use Spring Cloud Stream for both event sourcing and event stream processing using Apache Kafka.
Special Thanks
This article was a real challenge to put together, and because of that, I do want to thank a few people who helped it all come together.
First, I want to thank Chris Richardson for already contributing a majority of the existing content out there about event sourcing in microservices. I first started planning to put this project together a few months back after speaking at the Oakland Java User Group about Spring Cloud and microservices. Chris is the organizer of that group and he was in the audience during my talk. The audience was kind to me in the Q/A (which I appreciated!) and there were several questions about eventual consistency and how to share state between microservices. Chris was kind enough to bail me out for a few questions and provided details on many of the key points that I started researching as a part of this article and project. Chris has open source event sourcing examples available which I recommend taking a look at and you can find them here.
I also want to thank Ben Hale of the Spring Engineering team at Pivotal for being my guide when it came to putting together the reactive streaming examples for event sourcing using Project Reactor. I am fortunate to be able to have the privilege to work with so many brilliant minds behind the Spring open source ecosystem when I am putting together these articles and reference projects. If you want to get more involved with this amazing open source community please come visit us at our annual SpringOne Platform conference this August in Las Vegas.
No comments :
Post a Comment
Be curious, I dare you.